ES一文吃透
1 是什么?
一句话描述:ES在lucene的基础上,形成了分布式、高可用的开源搜索引擎。
2 核心概念
2.1 分布式架构
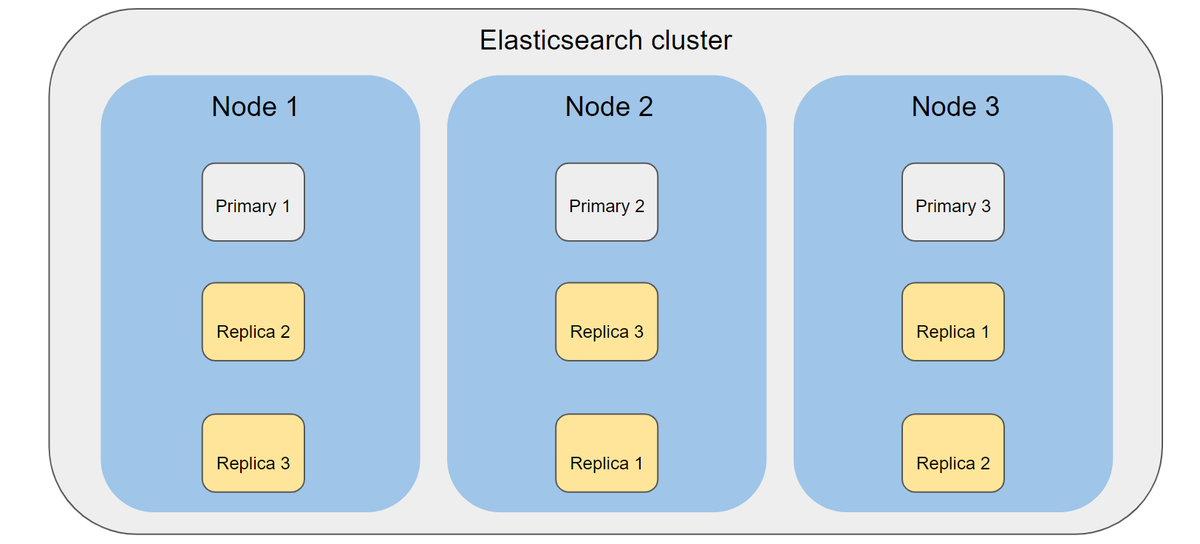
- Cluster: 集群,代表一个完成的Elasticsearch集群,由一个或多个节点组成
- Node: 节点,表示一个Elasticsearch集群中的一个基本单位,一个运行的实例。同时节点因分工不同具有不同的角色:master,data,client
- Index: 索引,逻辑概念,代表一组数据,类比database中的表名,具有自身结构字段描述数据(mapping)和配置(setting)
- Shard: 分片,对索引的横向扩展,一个索引可以分为多个分片,Elsticsearch 节点管理数据的基本单位
- Replica: 副本,同一个分片基于高可用的考虑会有副本,副本中分为主副本primary和从副本replica
- 类似其他分布式架构,ES内也有master选举、探活、恢复、水平扩容等特性。
2.2 倒排/TF-IDF等
这些可以看上一篇文章:Lucene
3 核心流程
3.1 查询
查询的过程,即输入query,返回所有相关文章。
简单流程就像这样:
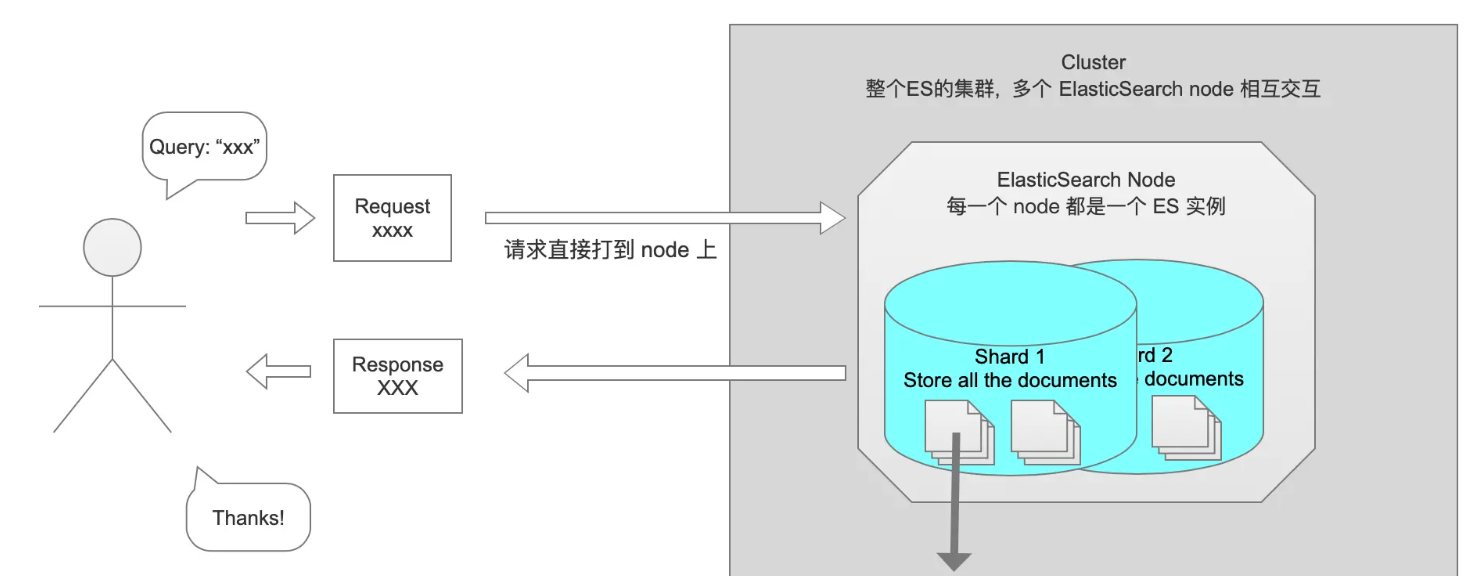
此时就会抛出第一个问题: 数量问题。比如,用户需要搜索”双黄连”,要求返回最符合条件的前10条。但在5个分片中,可能都存储着双黄连相关的数据。所以ES协调节点会向这5个分片都发出查询请求,并且要求每个分片都返回符合条件的10条记录。当ES得到返回的结果后,进行整体排序,然后取最符合条件的前10条返给用户。这种情况,ES5个shard最多会收到10*5=50条记录,整个过程中的成本是比较高的。
第二问题,排序。上面搜索,每个分片计算分值都是基于自己的分片数据进行计算的。计算分值使用的词频率和其他信息都是基于自己的分片进行的,而ES进行整体排名是基于每个分片计算后的分值进行排序的,这就可能会导致排名不准确的问题。如果我们想更精确的控制排序,应该先将计算排序和排名相关的信息(词频率等)从5个分片收集上来,进行统一计算,然后使用整体的词频率去每个分片进行查询。
这两个问题也没有什么较好的解决方法,把选择的权利交给用户,方法就是在搜索的时候指定query_type。
有三种查询手段:QUERY_AND_FETCH、QUERY_THEN_FETCH、DFS_QUERY_THEN_FETCH
1、query and fetch
协调节点向索引的所有分片(shard)都发出查询请求,各分片返回的时候把元素文档(document)和计算后的排名信息一起返回。这种搜索方式是最简单的,因为相比下面的几种搜索方式,这种查询方法只需要去shard查询一次。但是各个shard返回的结果的数量之和可能是用户要求的size的n倍。
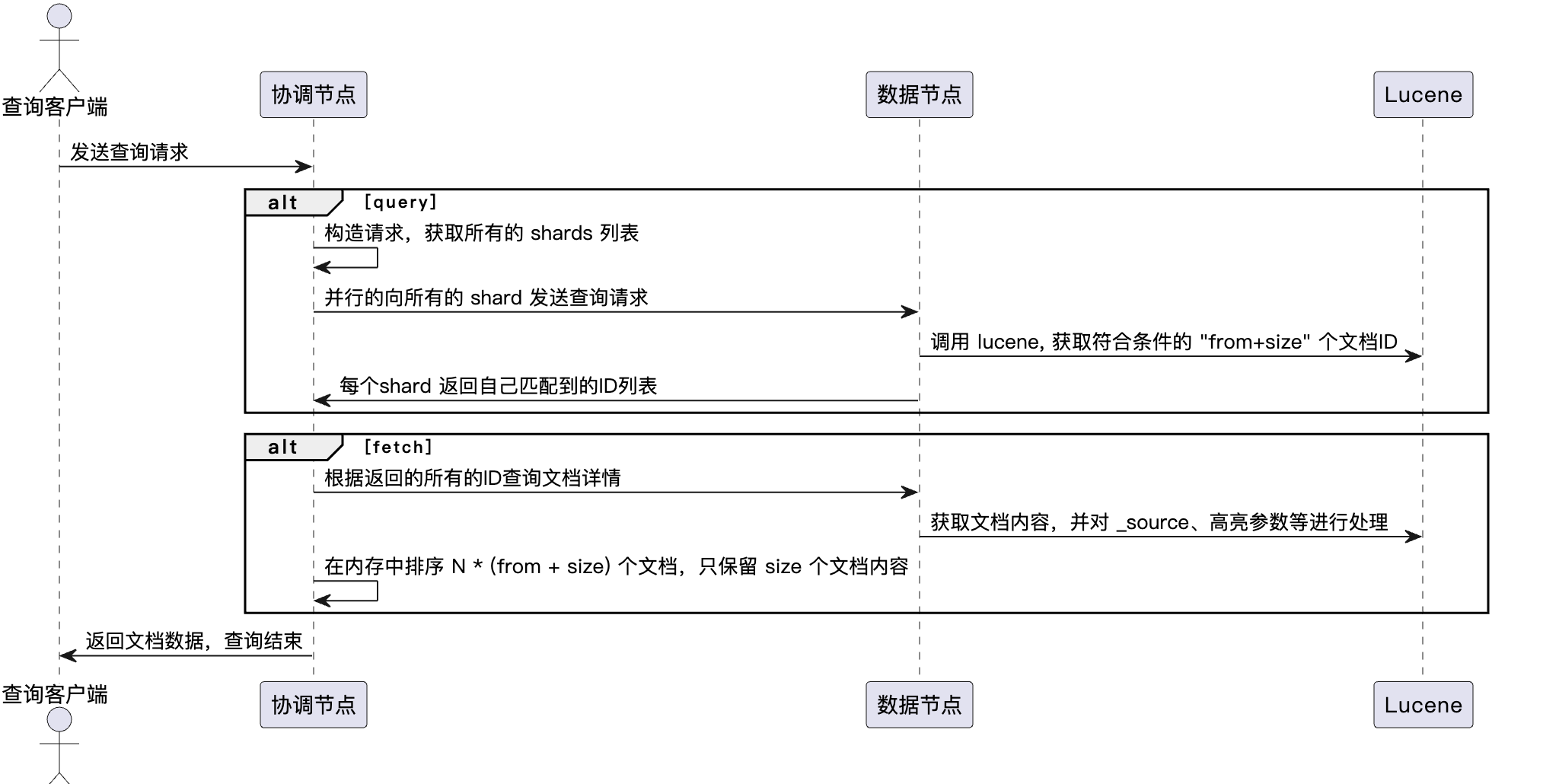
2、query then fetch(默认的搜索方式)
ES默认使用这种搜索方式。这种搜索方式,大概分两个步骤,第一步,协调节点先向所有的shard发出请求,各分片只返回docid排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,再次去相关的shard,根据docid取document。
- 调度是一个两阶段的过程,即先query再fetch:
3、DFS query and fetch
这种方式比第一种方式多了一个初始化散发(initial scatter)步骤,有这一步,据说可以更精确控制搜索打分和排名。从es的官方网站我们可以指定,初始化散发其实就是在进行真正的查询之前,先把各个分片的词频率和文档频率收集一下,然后进行词搜索的时候,各分片依据全局的词频率和文档频率进行搜索和排名。
3.2 写入
先来一个图:

3.2.1 文章路由
分布式的设计支持了海量数据的读写,那么当向索引中写入一个文档时,需要明确目标分片是哪个,文档分配的分片按照下面公式计算:
shard = hash(routing) % number_of_primary_shards
routing被称为路由值,是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。
3.2.2 近实时
参考上面的图和上一篇文章:Lucene,写入的文档会最快速写入最新的segment支持搜索到。 总结:倒排 + 内存独立的segment + 定期合并segment
3.2.3 存储可靠
每一次对ES的改动都会写入到 translog 中,与Mysql的binlog非常相似。在每一次对 Elasticsearch 进行操作时均进行了日志记录。默认在每次请求时都进行一次fsync操作将 translog 日志写入到磁盘中,这个写入过程在主分片和副本分片中都会进行。并且在整个请求被fsync到主分片和副本分片磁盘之前,写入请求不会收到200OK的响应,这也保证了每次数据写入不丢失。fsync是落盘操作,虽然是append语义,但是也有性能消耗,可以设置为并行执行和批量操作。
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
3.2.4 删除
Segment 是 Immutable(不可变)的, 所以删除和更新都不会更改旧 Segment 文件。 ES会维护一个 .del 文件, 当一个文档删除的时候, 会在 .del 文件中记录 Segment 1 中的 offset XX。 在搜索时, 每个 segment 中被标记删除的 Posting List 仍然会被搜索, 但是在最后将结果返回给其他 node 时会去掉。
https://zhuanlan.zhihu.com/p/94915597 https://bytetech.info/articles/6924954466550546439#heading13 https://bytetech.info/articles/7164745308856352781#doxcnYsYCkEgmmGOKaILOwHidqg
4 其他问题
-
如果两个doc很接近,导致算分一样,如何排序? 为了解决这个问题, ES 提供了 preference 参数 (一般配置为用户当前的 session ID), 在第一次搜索后, ES 会记录此次请求 Shard 的顺序以及一些搜索参数到缓存, 以 preference 参数为 key. 这样未来搜索保证同一个用户每次请求时 ES 访问 shard 的顺序始终是一致的
-
如何实现的doc部分更新?