Lucene一文吃透
1 是什么?
一句话描述:搜索引擎,以全文检索、倒排查询、可扩展性、高性能为卖点。
2 核心概念
索引库index
类似数据库的表的概念,一份已经被构建好的库。
文档doc
一个doc就是一条数据。 field是数据的字段。
段segment
一个index由多个segment组成,一个segment内包含多个doc。为什么分段?避免多个请求改动同一个文件,同时也可以增加建库和查询的效率。
一些细节内容:
segment是存储层的概念,在用户api层不涉及。设计思想与LSM类似但又有些不同。
Lucene中的数据写入会先写内存的一个Buffer(类似LSM的MemTable,但是不可读),当Buffer内数据到一定量后会被flush成一个Segment。
每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是Batch和Append,能达到很高的吞吐量。
文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID。
Lucene中对数据索引的构建会在Segment flush时,而非实时构建,目的是为了构建最高效索引。这也就是为什么Lucene被称为提供近实时而非实时查询的原因。
term
内容切词的最小单位称为term, 比如”今天天气真好”, 切为”今天” “天气” “真好”三个term。 term事实上就是doc的内容单元。
倒排索引查询reverse index
根据数据id查询数据属性,叫做正排查询。反过来,根据数据的一个属性查询数据id,称之为倒排查询。
相关性打分tf-idf
term-frequence,某个词在文档中出现的次数。 document frequency,某个词在多少个文档中出现。 simlarity = TF1IDF1 + TF2IDF2 + … + TFn*IDFn
准召
准确率=获取的正确的文档的个数 / 获取的全部文档的个数 召回率=获取的正确的文档的个数 / 库中正确文档的个数
分词analyzer
将输入的文档或者输入的查询串解析成tokens,在索引构建器或者查询器中被处理成term,进而进行索引或者查询。
Term Dict
存储所有的 Term 数据,同时存储也是 Term 与 Posting 的关系。
简单版:
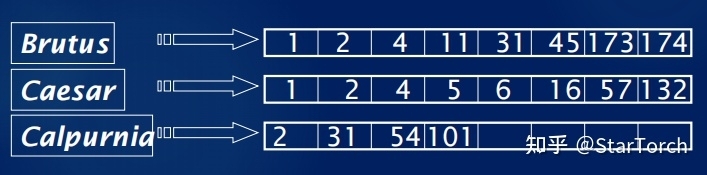
详细版:
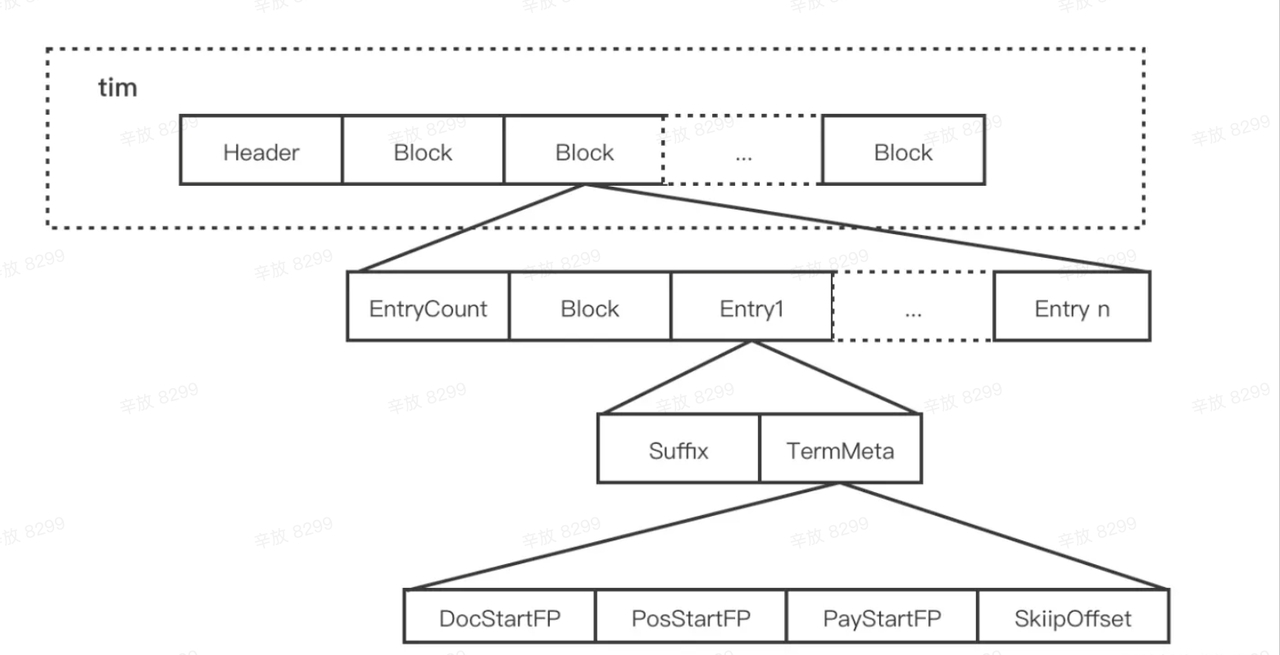
Posting
简单理解就是一个数组,存储了所有符合某个term的文档id。实际上,除此之外还包含:文档的数量、词条在每个文档中出现的次数、出现的位置、每个文档的长度、所有文档的平均长度等,在计算相关度时使用。 可以得到每个 Term 对应的如下信息:
- SkipOffset:用来描述当前 term 信息在 .doc 文件中跳表信息的起始位置。
- DocStartFP:保留包含每个Term的文档列表。
- PosStartFP:是当前 term 在文章中出现的位置信息。
- PayStartFP:是当前 term 在doc中的offset偏移/payload附加信息(如排序分数等) 存储上采用切分的多个文件。 逻辑上是用的跳表。
Term Index
Term Dict按顺序存储在文件中,如果term越来越多,查询效率就会很低。所以我们需要一个根据term找到其信息存储位置的索引结构。Lucene 采用了 FST 这个数据结构来实现这个索引。
真正存储时涉及的文件
段内的正排文件:tvx、tvd、tvf; 倒排信息:tis、tii、frq文件;
3 核心流程
在线查询(读)
先查内存中的segment,查不到再查磁盘中的segment,每个segment内执行:
简单版:
- 根据每个term,通过TermIndex查到是否存在以及位置
- 根据term和位置,通过TermDict查到posting
- 多个posting做拉链归并
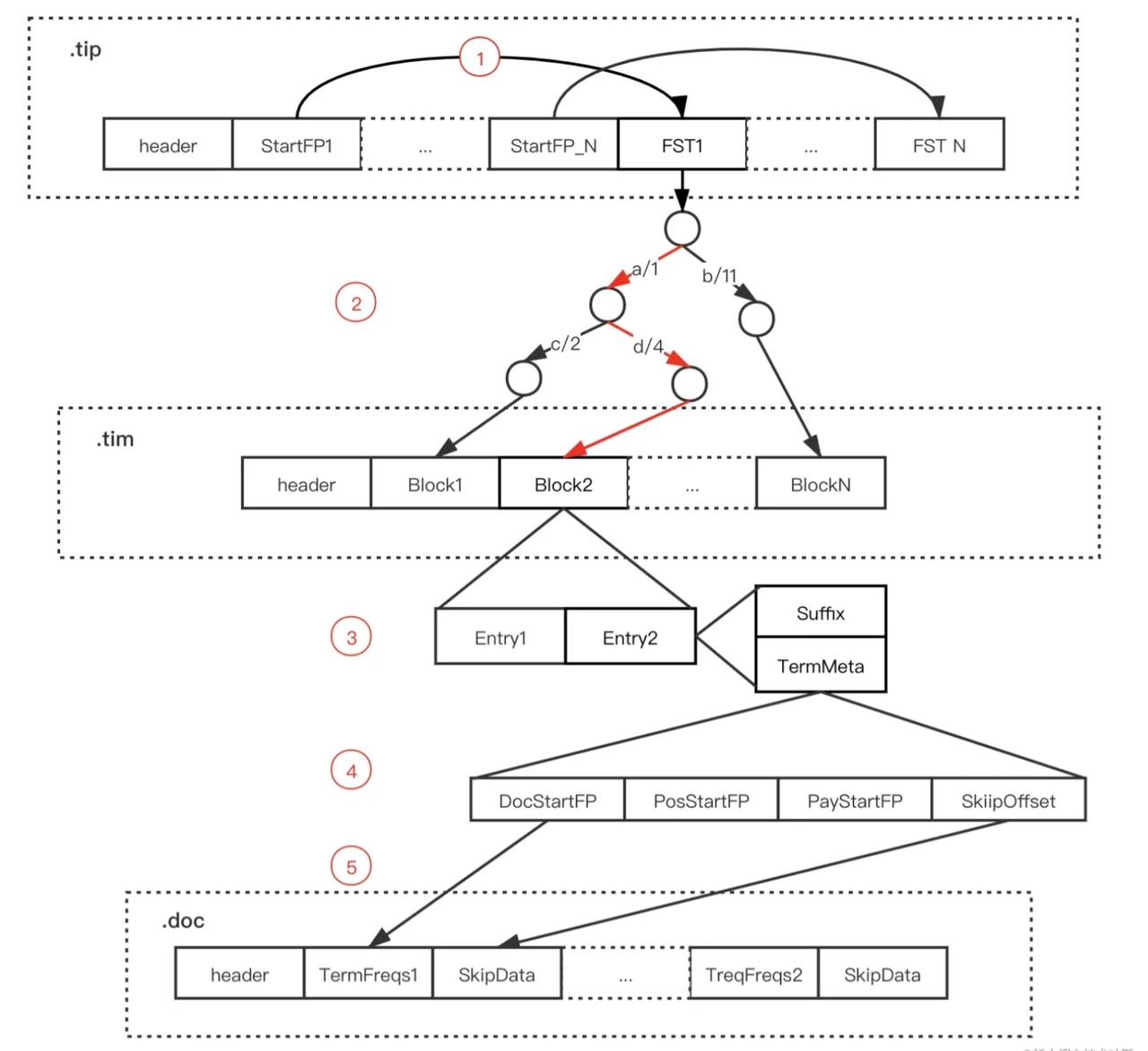
详细版:
- 通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
- 通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
- 将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
- 存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
- 按需求对posting做处理
(我的疑问1:这几步骤涉及的东西应该都加载内存吧?每次查询时加载也太慢了。) (我的疑问2:如果是直接查询id/其他唯一键呢?肯定涉及到跳表,但是在这之前应该先找到Block,怎么用id找Block呢?)
索引构建(写)
- Analyzer
- IndexWriter
- term写进TermIndex,同时找到block
- term和posting信息写进TermDict
- postinglist增加docId
- lucene flush/commit/merge
- Lucene flush, 会在fs cache层面创建一个segment来承载内存缓冲区中的文档,从而让这部分文档变成可搜索的, 默认执行频率是每秒。
- Lucene的commit操作,最终会对应到系统层面就是一次fsync调用。并生成Commit Point。代表了数据已经成功落盘,再也不会丢失了。这一点和DB的事务Commit含义是类似的。
- Lucene merge要解决因为Segment碎片化导致的搜索性能下降的问题。why?每次搜索都需要遍历所有的Segment; 而且Segment越多开销则越大,每个文件都需要占用文件句柄、内存、CPU等资源。
(我的疑问:merge的是还在cache层的segment吗?那commit时还未merge的怎么处理?commit不关心这些,而是直接把所有的cache内data全部落盘。而且merge的对象是commitpoint也就是已经落盘的文件。)
4 优化点
FST vs Skip vs Hash
- hash就不说了,桶+链表的方式其实就是用空间换查询时间。
- 跳表有共享前缀的思想,节省了空间,匹配思路其实是一种二分查找的链表。
- FST的优点是最大程度上对空间和时间进行平衡和优化,内存存放前缀索引、磁盘存放后缀词块,将全部term加载到内存,从而在内存中快速匹配前缀。而且在read/write流量都很大的情况下,能够尽可能少的改动内存中的结构,减少并发代价。
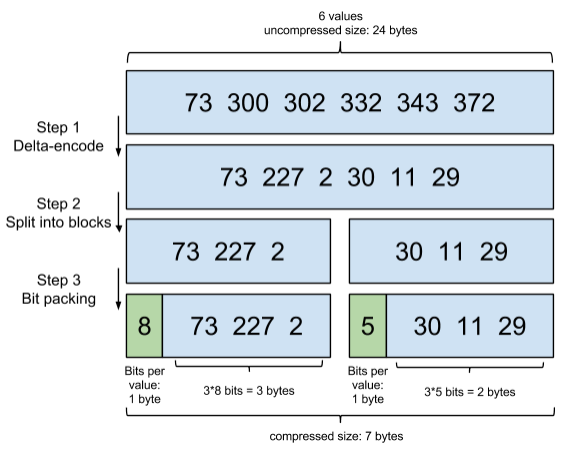
Frame Of Ref 压缩